
#FakePolls
Hay formas de hacer encuestas con las que uno puede coincidir o discrepar, pero hay procedimientos que solo producen encuestas truchas, detrito estadístico. Proponemos de ahora en adelante llamaras #FakePolls

02.01.2019 15:15

Después que se traspasa la aritmética básica: sumar, restar, multiplicar, dividir y poco más, se ingresa en un terreno donde la mayoría de la población no cuenta con herramientas para discernir sobre operaciones matemáticas de forma siquiera aceptable. Porcentajes, fracciones, tasas, probabilidades y otros conceptos bastante elementales resultan inaccesibles a un conjunto muy importante de individuos, que no solo no disponen del conocimiento necesario para realizarlos con precisión, sino que además no son capaces de valorar mínimamente si los cálculos y cifras a las que son expuestos son razonables o engañosos.
Tomemos como ejemplo los prestamos al consumo. A pesar de estar fuertemente regulados y del monitoreo del Banco Central, es muy fácil engañar a los consumidores no entrenados en matemática haciendo ensalada de cuotas, tasas y plazos. Prueba de ello es que este tipo de prestamos representa una porción muy importante de las quejas y denuncias ante defensa del consumidor.
Esto viene a cuento porque es lo que sucede con las encuestas. La mayoría absoluta de los ciudadanos no cuentan con los conocimientos matemáticos elementales para discernir si los números que publica una encuestadora son razonables o engañosos, confiables o dudosos, serios o basura. Abusando de esta debilidad, algunas empresas aprovechan para hacer pasar por encuestas sondeos de dudosa metodología y más dudosa ponderación, a las que extendiendo la idea de #FakeNews invitamos a denominar #FakePolls. Entre ellas, la reina absoluta e indiscutida es la encuesta basada en avisos en Facebook.
Una encuesta basada en avisos en Facebook
Ya hemos analizado largo y tendido las encuestas basadas en avisos en Facebook, como por ejemplo en Sobre las encuestas autopostuladas a través de Facebook y Sobre las encuestas basadas en avisos de Facebook II. Para complementar estos conceptos, nos tomamos el trabajo de hacer una encuesta basada en avisos en Facebook. Bueno, no es mucho trabajo al fin de cuentas.
La idea es simple: realizar una encuesta en la que conozcamos el censo, los datos duros, para poder valorar con precisión cuan representativos son los resultados que surgen de la muestra. Preguntamos para ello dos datos: el sexo, por ser una variable bipartida asimilable a un balotaje competitivo y el departamento de residencia, asimilable a un conjunto amplio de candidatos o listas. Preguntamos también la intención de voto, para completar un formulario creíble, pero por razones obvias tiramos a la basura los resultados de esta pregunta.
Realizar la encuesta de 1.000 casos fue muy sencillo: un formulario en Google Forms, y una campaña publicitaria en Facebook. Trabajo de una hora, un par de horas a reventar. Y es también muy barato, menos de 3.000 pesos por todo!!!
Como apunte de color, la cuenta de Facebook de “Investigadores Académicos Asociados” que realizaba la encuesta recibió comentarios, críticas e insultos, a pesar de no tener siquiera una publicación. El comentario de abajo es un botón de muestra de la seriedad de Facebook como medio para solicitar a la gente que llene una encuesta:

Los resultados
Según el censo realizado por el Instituto Nacional de Estadísticas, la población de Uruguay está compuesta de un 48% de hombres y un 52% de mujeres.
En nuestra encuesta de 1.000 casos, 684 respuestas fueron Mujer, 307 Hombre y el resto “Prefiero no decirlo”.
El departamento de residencia es igual de conflictivo. Abajo se muestra la tabla de población, comparando el peso de cada departamento en el censo y en la encuesta.
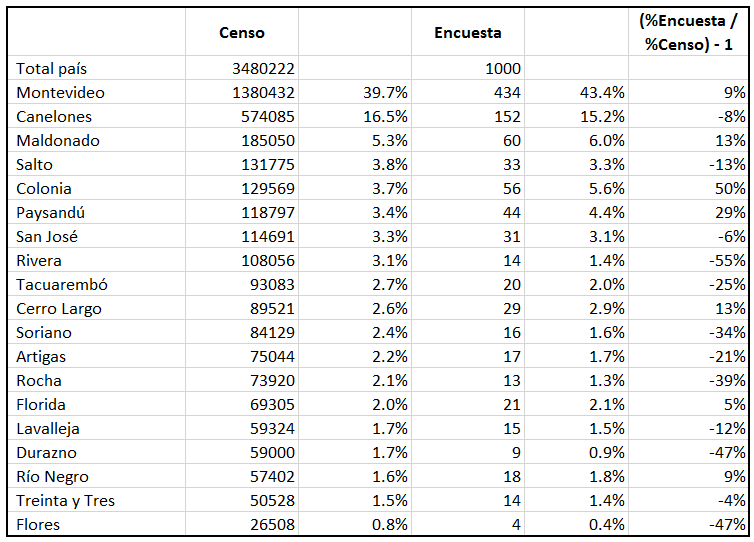
La pregunta a contestar es ¿Qué probabilidad hay de que ocurran diferencias como las obtenidas?
Empecemos por el sexo: la probabilidad de hacer una encuesta de 1.000 casos en una población con 52% de mujeres y obtener 684 tiene 25 ceros antes de la primera cifra significativa. La probabilidad de obtener 684 o más es del mismo orden de magnitud, porque a medida que aumentan las mujeres en la muestra, lo que estamos sumando es cada vez más pequeño. Dicho pronto y claro: el dato de 684 mujeres no es otra cosa que basura.
El tema de los departamentos requiere un poco más de cuidado. Para poder analizarlo determinamos un indicador de calidad de la muestra, calculado de la siguiente forma:
- Para cada departamento multiplicamos la cantidad de respuestas por el valor de (%encuesta / %censo) - 1 en valor absoluto.
Por ejemplo:
- Montevideo: 434 * 0.09 = 40.9
- Salto: 33 * 0.13 = 4.3
2. Sumamos los 19 valores y los dividimos por el tamaño de la muestra.
Cuanto mayor el indicador, peor es la muestra. Para el censo, este valor es exactamente 0. El valor para nuestra encuesta es 0.15. ¿Es este valor bueno o malo?
Para averiguarlo, simulamos 1 millón de encuestas que preguntan en qué departamento reside el encuestado con una población exactamente como la del censo y una muestra de 1000 casos.
El peor valor que obtuvimos fue 0.21, el mejor 0.02 y el promedio del indicador fue 0.09. Lo más significativo fue que solamente en 4167 casos el indicador fue igual o mayor que el de la muestra, lo que representa el 0.42% del millón de simulaciones.
Como era de esperar, una muestra aleatoria de 1000 casos tiene más problemas para representar los valores de una población dividida en 19 grupos que para dos grupos casi iguales, como en el caso del sexo. Pero nuestra encuesta basada en avisos en Facebook está muy lejos del promedio de una encuesta con muestra aleatoria. El 0.42% indica que no es imposible, no es basura, es apenas una porquería.
En resumen, la calidad de los datos que producen las encuestas basadas en avisos en Facebook abarcan un rango que va de la porquería a la basura. (perdón por lo poco académico de la expresión, pero la circunstancia requiere ser contundente).
Lo que la ponderación no corrige
No hay que caer en la trampa de que estos errores se corrigen ponderando. En esta encuesta se eligieron deliberadamente datos conocidos, pero en una encuesta lo interesante es a partir de una muestra proyectar a una población datos no conocidos.
Cuando quien hace la encuesta se enfrenta a los datos no tiene ninguna idea, ancla o referencia de cuáles son los datos válidos, con excepción de lo que dicen sus colegas.
Incluir en la encuesta otros datos conocidos (voto anterior es el más habitual) y ponderar por este valor no produce absolutamente nada: el sesgo no lo genera la política o la intención de voto o la disconformidad con el partido votado anteriormente. Ni siquiera los que mienten en la encuesta. Lo genera el motor de publicidad de Facebook, y eso no tiene relación alguna con el voto anterior. Es un pase mágico sin ningún fundamento que le permite a la empresa transformar de un plumazo la suma de porquerías y basura que obtuvo en algo parecido a lo que publican sus colegas.
Para tragarse ese sapo, es imprescindible que la ciencia te importe tres cominos.
#FakePolls = Depredación
Mientras los medios, los políticos, la academia, los empresarios y los ciudadanos sigan considerando las encuestas basadas en avisos en Facebook equivalentes a las encuestas de verdad, el costo comercial y de prestigio de recoger porquerías y basura, ponderarlas mirando a los colegas y publicarlas en un medio de comunicación será nulo. E inclusive muchas veces los medios pagan por esas encuestas.
El efecto es la depredación total del mercado. ¿Cómo competir con alguien a la que la ciencia le importa un comino, que configura una encuesta en una mañana, paga unos miles de pesos y en unos días publica los resultados a partir de los de sus competidores? Una encuesta de verdad es cosa seria: lleva mucho tiempo, esfuerzo y dinero planificarla, ejecutarla y procesarla. Si el mercado no ve la diferencia, el partido está perdido antes de empezar.
Si hubiera una ley de encuestas que obligara a publicar los datos crudos este problema no existiría, porque la ínfima calidad de las muestras obtenidas a partir de avisos en Facebook quedaría al desnudo, protegiendo la inversión y el trabajo de las empresas preocupadas seriamente por la ciencia, la investigación y la metodología detrás de los datos que publican.
Pero mientras no tengamos una ley de encuestas que obligue a publicar los datos crudos, hagamos el trabajo colectivo de identificar a las encuestas basadas en avisos en Facebook como lo que son, llamándolas por su verdadero nombre: #FakePolls.

Acerca de los comentarios
Hemos reformulado nuestra manera de mostrar comentarios, agregando tecnología de forma de que cada lector pueda decidir qué comentarios se le mostrarán en base a la valoración que tengan estos por parte de la comunidad. AMPLIAREsto es para poder mejorar el intercambio entre los usuarios y que sea un lugar que respete las normas de convivencia.
A su vez, habilitamos la casilla [email protected], para que los lectores puedan reportar comentarios que consideren fuera de lugar y que rompan las normas de convivencia.
Si querés leerlo hacé clic aquí[+]